|
|
1. デフォルト  2. 起動 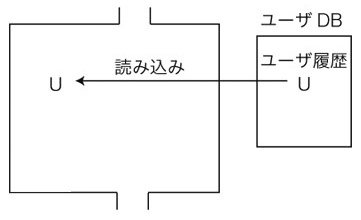
3. ユーザの入力テクストxに,応答テクストyを返す 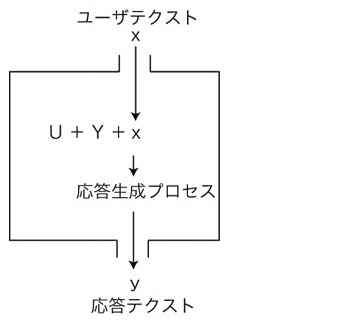
4. xとyを,Yに追加する: 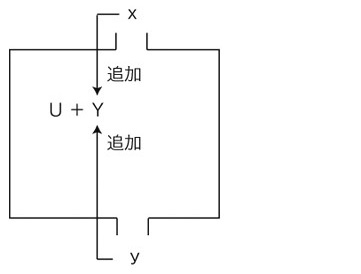
5. セッション終了: 
ChatGPT と Transformer は,「体」と「脳」の関係になる。 つぎは,Transformer の処理ではない。 ・始めの U の読み込み ・ x, y をYに追加 ・最後にYをUに追加 この処理にはテクストの要約も含まれているので,LLM 級のモジュールがこれをしていることになる。 Transformer の応答生成は,つぎのアルゴリズムになる:
↓トークン分割 [ t_1, ‥‥, t_m ] ↓対応するトークン点 [ x_1, ‥‥, x_m ] ┌→ [ x_1, ‥‥, x_m ] │ │ │ 生成終了?── YES ───→ 応答出力 │ │NO │ │← 位置エンコーディング加算 │ ↓ │ x_i^(1) = x_i ( i = 1, ‥‥, m ) │ x_i^(ℓ) │ ├─────┐ │ │ Self-Attention │ │ ↓ │ │ z_i^(ℓ) │ │ │← LayerNorm │ │← 加算 ─┘ │ │ │ ├─────┐ │ │ FFN │ │ ↓ │ │ z'_i^(ℓ) │ │ │← LayerNorm │ │← 加算 ─┘ │ ↓ │ x_i^(ℓ+1) │ x_i^(NL) │ ↓← Self-Attention, FFN │ o_i = x_i^(NL+1) │ ↓ │ logis │ ↓ │ [ p_1, ‥‥, p_m ] │ p_m : 「x_m の次は x_(m+1)」 │ │ └────┘m = m+1 ここで, ┌──────┼──────┐ ↓線型変換 ↓ ↓ Q_i = x_i W_Q K_i = x_i W_K V_i = x_i W_V └──┬───┘ │ ↓ │ α_i = sim( Q_i ; K_1, ‥‥, K_m ) │ │ │ └───┬──────┘ z_i = α_i V ↓← LayerNorm sim( Q_i ; K_1, ‥‥, K_m ) = softmax( Q_i (K_1)^T/√D, ‥‥ , Q_i (K_m)^T/√D ) ・FFN ↓ z'_i = σ( x_i W_1 + b_1) W_2 + b2 ↓← LayerNorm ・[ p_1, ‥‥, p_m ]
p_i = softmax( logits_i ) このアルゴリズムは,<"Training" モードの Transformer>のアルゴリズムのうちの「順伝播」を,ループさせたものである。 <"Training" モードの Transformer>は,トークンベクトルと各種重みの値を「逆伝播」のアルゴリズムで更新する。 これが, 「脳の成長」の意味になる。 この成長を止め ROM にしたのが,ChatGPT の Transformer 脳である。 ChatGPT は,この ROM の中の ユーザの入力テクストに対する応答テクストの出力は,その都度,決定論である。 しかしこの決定論は,複雑系の決定論である。 複雑系の決定論は,「決定論」として考えることができない。 この意味で,ChatGPT の動作は,決定論であって決定論ではない。 この押さえは,ChatGPT の論を地に足のついたものにする上で,ことのほか重要である。 |